
Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please contact us to request a format other than those available.
A New Approach for the Development of a Public Use Microdata File for Canada's 2011 National Household Survey
4. Application of the data perturbation strategy
This section provides more information on the application of the data perturbation strategy, starting with the application of the risk measure.
4.1 Application of the disclosure risk measures
DIS risk measures were generated for both individuals and households. Disclosure risks for individuals were calculated only for members aged over 15 since little information was provided about younger members other than age, sex and ethno-cultural characteristics. Younger members would be covered by household level analyses and by the additional treatment of ethno-cultural variables. The risk analysis for individuals was done by subgroup defined by province, rural indicator, and sex. Within each subgroup, scenarios involving 16 IVs taken one, two and three at a time were used to calculate the DIS(5). IVs used were not necessarily variables as present on the PUMF. Quantitative variables like age and income were grouped into categories. Other variables were merged for convenience (e.g., Aboriginal identity was combined with DVM and the English/French mother tongue variables were combined with MTN). While the PUMF does not directly identify couples, some couples could be formed using the variables Relation to Person 1 (R2P1) and Marital Status. This allowed a distinction to be made between same sex and opposite sex unions in the IV marital status. Less than 1% of the approximately 770,000 respondents aged over 15 had a DIS(5) value above our risk threshold.
Using couples as formed above, household level risks were generated for four types of households: one-person households (around 98,000 households), one-couple households (216,000), multi-couple households (4,000) and other (no-couple) households (53,000). A set of IVs and subgroups was created for each household type. For one-couple households subgroups were defined by province, rural indicator, sexes of the couple (MM, MF, FF), and a variable called household class. Household class had categories such as couple only, with children (only), with one parent, with grandchildren, with a parent and children, with children and grandchildren, and various types of multi-generational households with one couple. The presence of unrelated members generated more household classes. There were 24 IVs including household size (slightly grouped), household income group, the couple's joint education, occupation or ethno-cultural characteristics, combined characteristics of their children or other members, dwelling characteristics, etc. Some variables, like the age-sex distribution of children, had hundreds of categories. As expected, the risk was much, much higher when working at the household level. Nearly 40% of the one-couple households had DIS(5) above our threshold, including several thousand with an estimated risk of 100%. For a large proportion of the households at risk, removing the IV for the joint occupation of the spouses brought the risk value DIS(IV) below our threshold.
Only about 4% of one-person households were above our risk threshold. The risk analysis for those households was done for 18 IVs, with subgroups formed by crossing province, rural indicator, and sex.
Results for the third largest group, no-couple households, were closer to those for one-couple households, with over 30% of household at risk. For these households 21 IVs were used and subgroups based on province, rural indicator, and household class. Household classes were lone-parent households, lone-grandparent households, three-generation households, other lone parents living with relatives, lone parents living with non relatives, other households of related individuals only, households of unrelated individuals only, other households with children, and other households. The IVs were created in a fashion similar to one-couple households.
The analysis for multi-couple households used 22 IVs and subgroups defined by region (Atlantic, Quebec, Ontario, Manitoba+Saskatchewan, Alberta, B.C., and the North) and household class, which could take up to 48 different values. The combination of small sample and multi-valued IVs and subgroups meant that all the households exceeded our risk thresholds; and for over 4/5th the risk was 100%. Based on earlier studies involving hierarchical PUMFs these results were not surprising.
Once persons and households at risk were identified the next step consisted of identifying the variable or variables to perturb, as described in Section 3.3. For multi-member IVs, such as spouses' OCC, it was also necessary to choose which member(s) to perturb. Often OCC was singled out for perturbation. To reduce the extent of perturbation for this variable an alternate variable was selected whenever possible. Also, when the risk was not much higher than our threshold, perturbation was not carried out on a 100% basis. Perturbation was also avoided for some other variables in this step. This was the case for POB, MTN and DVM. These variables are extremely complicated to perturb because of the multiple relationships that exist between them (and with other variables like citizenship and religion) and between household members. Moreover, these variables were already subject to perturbation as a result of the ethno-cultural analyses (see Section 4.3).
Advantage was taken from the fact that variables such as income and occupation were imputed much more often than others on the 2011 NHS (around 10% for OCC). When these variables were imputed on the 2011 NHS, their values were treated as if they had already been perturbed, which was often enough to designate the unit as protected. (It may have been useful to include the fact that the values were imputed when calculating the risk, but there was not an easy way to do that.)
4.2 Perturbation of units at risk
Four types of perturbation were carried out. The simplest was the addition of random noise to quantitative variables like Age and income. When an income variable was selected for perturbation, its value was usually multiplied by a factor 1+ε, where ε was a random noise that followed the split triangular distribution (shaped like 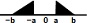 ). The perturbation of age was done in a similar way except for individuals aged 15 to 33, whose perturbation was made to better reflect their age distribution by marital status and highest degree completed (HCDD). Instead of perturbing those ages in each direction 50% of the time, the perturbation probabilities followed the age distribution of people with the same marital status in neighbouring ages. So a married 18 year-old would be much more likely to have his age increased rather than decreased.
). The perturbation of age was done in a similar way except for individuals aged 15 to 33, whose perturbation was made to better reflect their age distribution by marital status and highest degree completed (HCDD). Instead of perturbing those ages in each direction 50% of the time, the perturbation probabilities followed the age distribution of people with the same marital status in neighbouring ages. So a married 18 year-old would be much more likely to have his age increased rather than decreased.
The second perturbation method was swapping, which had the advantage of preserving univariate statistics. Swapping was applied to individual variables or to sets of variables between persons, to persons between households, and to households between regions. When the number of units to be swapped allowed it, efforts were made to swap among similar units. This could be achieved in two ways. First, swapping could be done within swapping cells created by crossing variables such as region, sex, income or education level. Second, units within a swapping cell could be sorted by an ordinal variable like income or education, so that individuals with the lowest/highest values for that variable would tend be swapped together. Proper swapping required a fair amount of preparation. For example, to swap the OCC of individuals in such a way that swapping partners never shared the same OCC, a minimum requirement was that a swapping cell could not have more than 50% of its members with the same OCC. If necessary, swapping cells could be collapsed or merged, or individuals could be moved to/from neighbouring swapping cells until the requirement was met.
The third perturbation method was the application of a specific change to a randomly selected set of units. For example, among households for which it was decided to change the number of children, a specific number were randomly chosen to gain children and the rest would lose children. Finally, deterministic and random perturbations were carried out. Such perturbations were particularly used in the treatment of ethno-cultural variables, which is described in Section 4.3.
The variable with the highest number of perturbation swaps was OCC. To minimize the impact of OCC swapping on different types of analyses, two swapping approaches were used more or less the same number of times.
The first consisted of clustering occupations and swapping OCC values within clusters. Using generalized principal components (PRINQUAL procedure in SAS®) we formed 21 classes of OCCs that are similar in composition, i.e., their mix-up of individuals with respect to POB, DVM, religion, year of immigration, income group, HCDD, field of study, region, age and sex. OCC swapping was done within OCC class, HCDD, and sex. When necessary to ensure full matches, some collapsing or category "jumping" was done. The clustering was used as much as possible. However, about a quarter of individuals had occupations that were alone in their class. OCC swapping for these individuals was carried out within groups generated using sex, employment income, rural indicator, and HCDD.
The second swapping approach was similar to one used by the U.S. Census Bureau and Westat (Krenzke, Li, and Zayatz, 2013). We formed swapping cells of individuals using a cross-classification of relevant variables. The most important variable is what Krenzke et al. (2013) call the cluster or prediction group. This is a grouping of individuals so that the individuals in the same group have similar predicted probabilities of belonging to the 70 different OCCs. The probabilities of belonging to different OCCs were modelled based on covariates POB, MTN, DVM, religion, year of immigration, income group, HCDD, field of study, region, age, sex, full time/part time work status, and school attendance. The subjects were then classified into 70, 58, and 25 groups according to their predicted probabilities.
Finally, swapping cells were created using the cross-classification of prediction group (70, 58 or 25, depending on donor pool size), income group, either skill type or skill level, sex, region, and survey weight group. Swapping was carried out within swapping cells as much as possible, but some collapsing of the least important variables was allowed when necessary. For a small percentage of cases the HCDD of the swapping partners were far apart. We redid the swapping for those individuals controlling for sex, HCDD, income group and, when possible, the 25-level prediction group.
The use of clustering helped to maintain relationships between OCC and related variables on the PUMF. To better preserve specific relationships, some variables were swapped alongside OCC. This was not done always, as there was a trade-off between preserving a variable's relationship with OCC on the one hand, and preserving its relationships with all other variables – and the desire to minimize overall perturbation rates – on the other. Industry (IND) was swapped alongside OCC always, and Field of study, most of the time. HCDD was swapped with OCC when the swapping partners were not sufficiently close with respect to HCDD, which was more likely when HCDD was not used in the original swapping.
Swapping was also used, to a smaller extent, for dichotomous and nominal variables at risk. Instead of swapping, perturbation for ordinal variables such as HCDD usually consisted of replacing values by neighbouring categories. This was done in a balanced manner to maintain marginal distributions as much as possible.
Aside from the random perturbation of Age, controls were applied to unusual differences in the ages of spouses and in the ages of parents and their children. The population distribution was used to set top and bottom codes for differences in spouses' ages. Great differences were reduced by changing one or both spouses' ages. A similar treatment was done for unusual differences in parent-children ages.
The most severe perturbation methods were used on unresolvables and on households at risk because of ethno-cultural variables but for which we did not want to change such variables. Methods used included changing the sex of members, changing their "life stories" (essentially the occupation and education variables), swapping persons between households, adding/removing children, and swapping geography. Swapping was usually carried out between similar persons/households.
4.3 Treatment of ethno-cultural variables
Ethno-cultural variables, particularly POB, MTN, DVM and religion can be problematic because they are more visible and because there are strong relationships between those variables for individuals and within households. Rules based on population thresholds were applied to those variables to identify individuals and households at risk. Examples are: values that are rare for their province; rare combinations of variable values for an individual; households with more than two category values for a variable (other than the commonest categories like POB in Canada, English or French MTN, not a visible minority…); rare mixes of values for spouses or within households, etc. In treating these rare cases we aimed to perturb the fewest members and values possible, but also wanted to respect relationships between variables and members. When a characteristic's value was changed the change usually affected all relatives with that value.
POB was easiest to change because its relationship between members was the weakest. Its large number of categories also made it the riskiest ethno-cultural variable. It was difficult to change DVM or MTN without changing POB as well (unless the change was to make these variables more "compatible"). Although the total number of perturbations was reasonably small, the treatment of rare cases did have an impact on the data. Univariate frequencies were generally not affected by much, although the rarest categories were affected the most. For POB (with Canadian POBs combined), MTN, DVM and religion, if we exclude the categories "Unspecified – Person lives in Northern Canada", the net impact of perturbation was never above 3%, and it was above 1.2% only 5 times.
Treatments for multiple and/or rare combinations of values within a household did make households slightly more homogeneous (e.g., households with too many POBs had POBs dropped). Rare combinations of variable values usually had one variable/value replaced, preferably by another value present in the household. This may reduce the occurrence of unusual cases such as immigrants from Europe whose visible minority status is of Asian origin.
Changes to POB and MTN sometimes triggered changes to other variables such as religion, citizenship, POB of Father/Mother, home language and language at work. POB perturbation was usually carried out separately for persons born in Canada and elsewhere to avoid having to change year of immigration.
- Date modified: